Deepseekの驚くほど安価なAIモデルは、業界の巨人に挑戦しています。同社は、2048 GPUを使用してわずか600万ドルで強力なDeepSeek V3ニューラルネットワークを訓練したと主張しており、競合他社を大幅に下げています。しかし、この数字は誤解を招くものです。
 画像:Ensigame.com
画像:Ensigame.com
Deepseek V3は革新的なテクノロジーを活用しています:マルチトークン予測(MTP)精度と効率を向上させるため。 256のニューラルネットワークを利用して、トレーニングを加速し、パフォーマンスを向上させるために、256のニューラルネットワークを利用している専門家(MOE)の混合。 マルチヘッドの潜在的な注意(MLA)**重要な文要素に焦点を当て、情報の損失を最小限に抑えます。
 画像:Ensigame.com
画像:Ensigame.com
彼らの最初の主張に反して、SemianalysisはDeepseekの広範なインフラストラクチャを明らかにしました。これは、複数のデータセンターにわたって約50,000のNVIDIAホッパーGPUを含み、約16億ドルの総投資と9億4,400万ドルの投資を表しています。これには、人員への多額の投資が含まれ、一部の研究者は年間130万ドル以上を稼ぎます。
 画像:Ensigame.com
画像:Ensigame.com
中国のヘッジファンドであるHigh-Flyerの子会社であるDeepseekは、データセンターを所有しており、より多くの管理とイノベーションの実装を高めることができます。この自己資金によるアプローチは、その敏ility性に貢献しています。 600万ドルの数値は、研究、洗練、データ処理、インフラストラクチャを除く、トレーニング前のGPUコストのみを反映しています。 DeepseekのAI開発への実際の投資は5億ドルを超えています。
 画像:Ensigame.com
画像:Ensigame.com
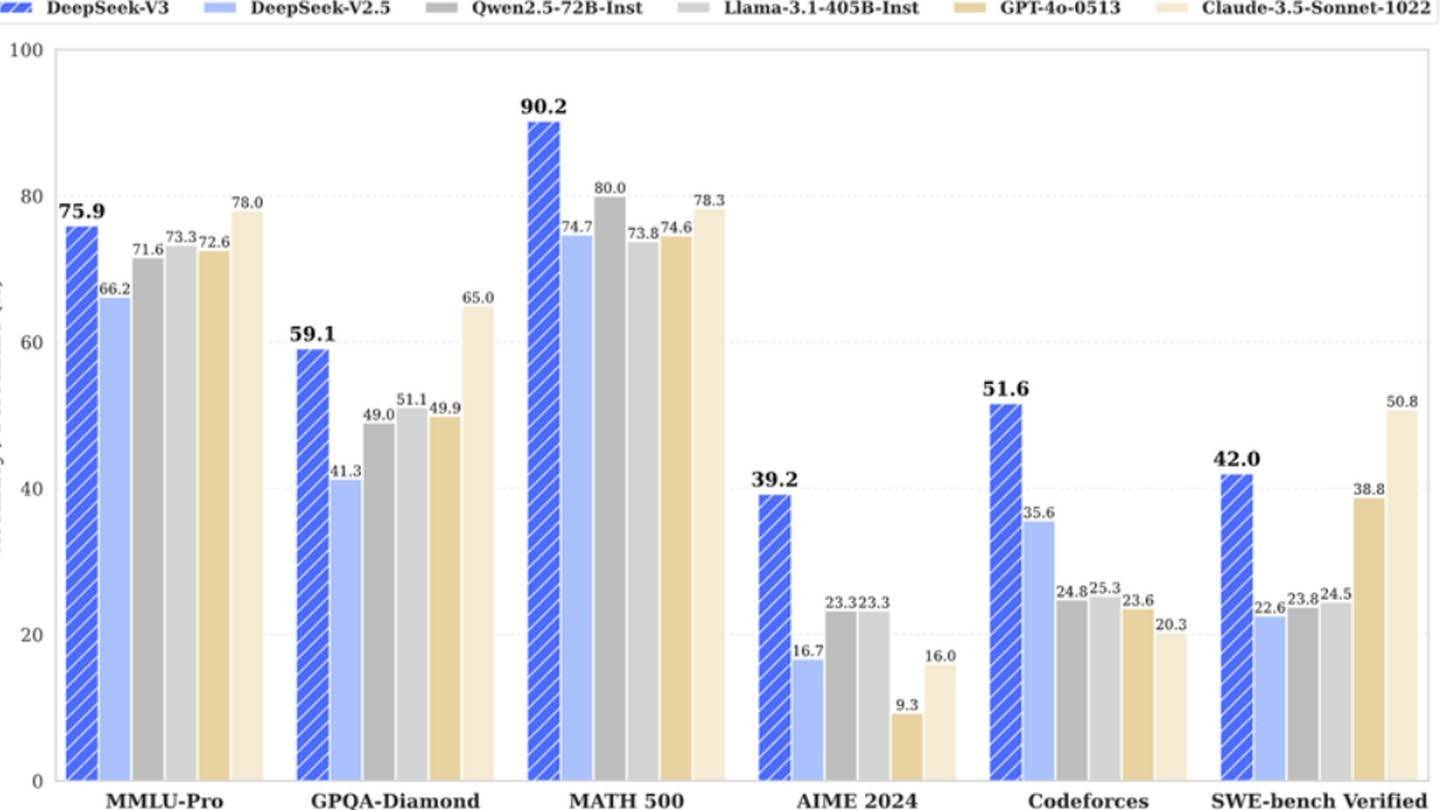
Deepseekの成功は、実質的な投資、技術の進歩、熟練したチームに由来していますが、その「予算に優しい」物語は単純化しすぎです。ただし、修正された数字があっても、競合他社と比較して、Deepseekのコストは依然として劣っています。たとえば、DeepseekのR1モデルはトレーニングに500万ドルの費用がかかりますが、ChatGPT-4は1億ドルかかります。ただし、同社の効率性と焦点を絞った構造により、関与する多額の投資にもかかわらず、業界の巨人と効果的に競争することができます。





